Navigating Data Science Projects: Overcoming Junk Data Issues
Written on
Chapter 1: The Frustration of Data Science Projects
Many aspiring data scientists encounter a disheartening reality: despite having honed their technical skills, their project ideas often fall flat. It begs the question: why do some data sets seem to hinder rather than help our projects?
As part of my ongoing series, I aim to address a commonly faced dilemma in data science. This column avoids clichés and sensational headlines, instead offering genuine insights drawn from my professional experience and technical knowledge.
In February 2021, I found myself jolted back to reality by the all-too-familiar sound of a file being discarded into the digital trash. I was faced with yet another collection of loosely connected information that I struggled to classify as actual data. Data should be precise and revealing, yet what I had was merely a jumble of bytes. As I glanced at the more than 20 tabs open in my browser—15 of which were Kaggle searches—it became evident: my current approach was ineffective and the data I had was not suitable for my intended use.
Disheartened, I reverted the title of my final project presentation to “TBD” and proceeded to download yet another file.
For those who have navigated a data science program, this scenario may resonate deeply, perhaps even evoke a sense of trauma. For students and novice data practitioners, the ability to discern between valuable and "junk" data often develops at a slower pace than their other technical skills.
Experiencing the frustration of developing a promising project—whether a personal endeavor or an academic assignment—only to discover that the available data does not align with your needs is disheartening. Once is annoying, but repeatedly sifting through unusable files can be truly demoralizing.
Before we delve deeper, it’s crucial to clarify that the notion of a project “not working” is not a binary issue. Data-driven projects are inherently subjective, influenced by numerous variables, and even the most successful projects often leave room for further refinement. Sometimes, even a project that appears near-perfect may still harbor aspects that don’t quite fit.
Here, I’m referring to those frustrating, hair-pulling projects that seem impossible to piece together, where the real issue often lies not in your project design or technical skills, but in what I refer to as junk data.

Chapter 2: Understanding Junk Data
As I hinted at earlier, junk data encompasses any data source that appears to be a complete dataset but is ultimately ineffective. Think of that CSV file with four fields where three of them are strings, or a massive 4 GB file containing features that bear no relation to one another.
Junk data can be particularly alluring due to its easy accessibility. Platforms like Kaggle are filled with such data, not because they are poor resources, but because users can upload their datasets without providing adequate context for their intended use. Additionally, it's likely that most users are not sharing thoroughly cleaned or refined datasets, often providing files that are either mistakenly downloaded from other sources or leftover from their own projects.
This leads me to caution against relying too heavily on Kaggle. While it has its merits, there seems to be an abundance of junk data available.
Even APIs, which I typically advocate for personal projects, can deliver useless data. Conducting an open-ended query on a general endpoint often yields a vast amount of data, but upon closer inspection, you may find that 80-90% of the fields are irrelevant to your specific use case.
Web scraping, such as extracting tables from Wikipedia, can also present challenges. These tables often contain fewer than 100 rows, necessitating an extensive data collection effort to achieve a substantial and diverse sample.
Beyond source data complications, issues can also arise during dataset creation, further exacerbating the accumulation of junk data. You may find yourself with several CSV files that appear valuable in isolation but cannot be merged due to missing primary keys, or a nested JSON structure that proves difficult to convert into a more usable format.
Having experienced these challenges firsthand during my graduate studies, I can relate. For my capstone project, I navigated through an overwhelming amount of junk data, leading me to change my topic multiple times and discard gigs of data along with numerous pages of Jupyter Notebooks.
Ultimately, I learned that you can't force a project design into existence. While selecting high-quality source data can alleviate many frustrations, it is not a foolproof solution.
To ensure your project is successful, it's essential to have a clear understanding of your end goals and the insights you aim to derive.
Often, academic assignments impose certain requirements on students, such as a specific number of visualizations or the need to merge a set number of datasets. I find these stipulations too broad and would advise against adhering to them rigidly in your own project planning.
Instead, concentrate on identifying or creating data sources that address specific questions, such as:
- How many users are likely to churn based on certain features?
- Which product slogan is optimal according to the top Google keyword searches?
- What price point would have attracted more attendees to the Vegas Grand Prix?
These questions are both open-ended and free from rigid requirements like "train a regression model" or "create a bar chart." While I understand the rationale behind schools setting specific output criteria, they can sometimes stifle creativity and lead to frustration when they feel forced into an otherwise sound project design.
If you find yourself feeling particularly stuck, consider rephrasing your project topic as a question rather than a statement. Following that, generate three to five additional questions that you would need to address to fulfill your original goal. By undertaking this exercise, you can gain a more nuanced perspective on the data required, allowing you to eliminate any junk.
For those interested in understanding my approach to conceptualizing data-oriented projects, I recently developed a project ideation guide. It’s concise, spanning just five pages, and provides examples for those embarking on personal projects in data science, data analysis, and data engineering.
The objective is to encourage you to think less like a student completing an assignment and more like a professional addressing a business case.
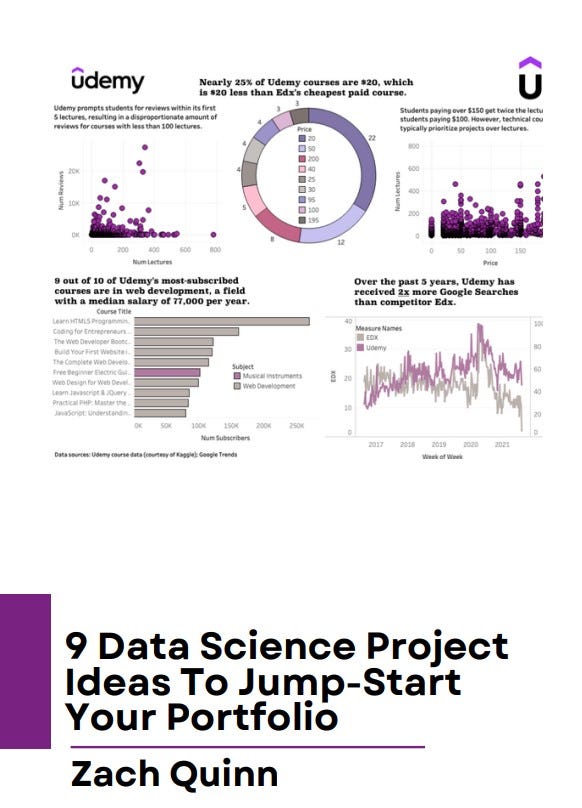
The first video titled "How I Start Data Science Projects | What to Do When You're Stuck" provides insights into tackling project challenges and offers practical strategies for overcoming obstacles.
The second video, "Why 99% of Portfolio Projects Are Useless - Data Science," discusses common pitfalls in project selection and how to create impactful portfolios.