Exploring Greedy Search Decoding for Text Generation in Python
Written on
Chapter 1: Introduction to Text Generation
In today's digital landscape, engaging with chatbots has become a commonplace experience. Thanks to the emergence of transformer-based language models, these systems can generate text that closely resembles human writing, from casual conversations to humorous exchanges. The ability of Natural Language Processing (NLP) models to produce coherent text hinges on their decoding methods, which transform probabilistic outputs into readable text.
This article will focus on one prevalent decoding technique: greedy search decoding.
Section 1.1: Understanding Greedy Search Decoding
Greedy search decoding operates by selecting the word with the highest probability at each timestep. For instance, if the first word generated is "Pancakes," the algorithm will subsequently choose the next word based on the highest probability, continuing this process for the specified number of timesteps.
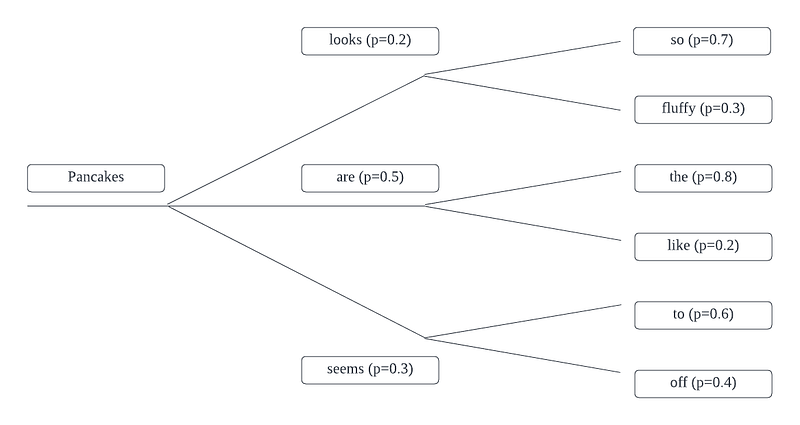
Using the probabilities of the words chosen, the final sequence generated may be "Pancakes are the," with an overall probability calculated as 0.5 * 0.8 = 0.4 (or 40%).
Section 1.2: Implementing the Algorithm with GPT-2
Let's explore how this decoding method functions using the pre-trained weights from the OpenAI GPT-2 model. Depending on your GPU's memory capacity, you can choose the lighter gpt2 model (approximately 500MB) or the more extensive gpt2-xl (about 5.9GB).
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model_name = 'gpt2-xl'
# Use 'gpt2' if you encounter memory issues
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
Before selecting a model, it's wise to check your GPU's current memory allocation to avoid potential errors.
from pynvml import *
def print_gpu_utilization():
nvmlInit()
handle = nvmlDeviceGetHandleByIndex(0)
info = nvmlDeviceGetMemoryInfo(handle)
print(f"GPU memory occupied: {info.used//1024**2} MB.")
print_gpu_utilization()
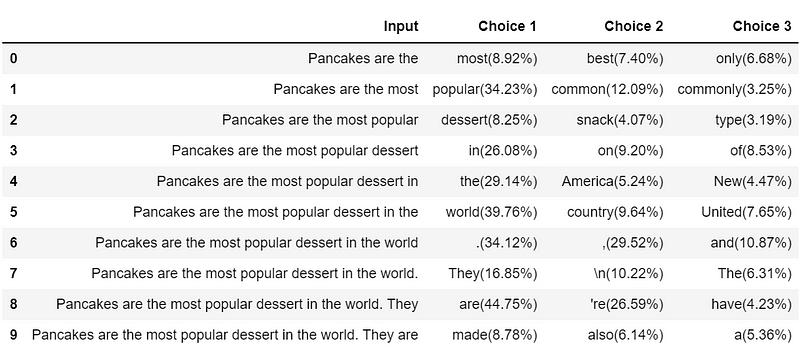
With the model ready, we can proceed to execute the decoding process. The following function applies a softmax to obtain the probability distribution for each batch, sorts the tokens in descending order, and appends the token with the highest probability to our input sequence for each timestep.
import pandas as pd
input_sentence = 'Pancakes are the'
input_ids = tokenizer(input_sentence, return_tensors='pt')['input_ids'].to(device)
iterations = []
n_steps = 10
choices_per_step = 3
with torch.no_grad():
for _ in range(n_steps):
iteration = dict()
iteration['Input'] = tokenizer.decode(input_ids[0])
output = model(input_ids=input_ids)
next_token_logits = output.logits[0, -1, :]
next_token_probability = torch.softmax(next_token_logits, dim=-1)
sorted_ids = torch.argsort(next_token_probability, dim=-1, descending=True)
for choice_idx in range(choices_per_step):
token_id = sorted_ids[choice_idx]
token_probability = next_token_probability[token_id].cpu().numpy()
token_choice = (f"{tokenizer.decode(token_id)}({100*token_probability:.2f}%)")
iteration[f"Choice {choice_idx+1}"] = token_choice
input_ids = torch.cat([input_ids, sorted_ids[None, 0, None]], dim=-1)
iterations.append(iteration)
pd.DataFrame(iterations)
And here’s the output from the above code:
Section 1.3: Utilizing the Generate Function
Alternatively, we can use the built-in generate function for greedy search decoding, which simplifies the process.
input_sentence = 'Pancakes are the'
n_steps = 10
input_ids = tokenizer(input_sentence, return_tensors='pt')['input_ids'].to(device)
output = model.generate(input_ids, max_new_tokens=n_steps, do_sample=False)
print(tokenizer.decode(output[0]))
The output generated is as follows:

Section 1.4: Generating Longer Texts
If you wish to generate a more extended paragraph, simply adjust the maximum length parameter.
input_sentence = 'Pancakes are the'
max_sequence = 100
input_ids = tokenizer(input_sentence, return_tensors='pt')['input_ids'].to(device)
output = model.generate(input_ids, max_length=max_sequence, do_sample=False)
print(tokenizer.decode(output[0]))
The output from this function is as follows:

It's important to note that the generated text may contain repetitions, such as "The recipe for the Pancakes…", due to the limitations of the greedy search decoding algorithm, where higher-probability words often precede those with lower probabilities.
Despite this limitation, greedy search decoding can still be valuable for generating shorter text sequences that require factual accuracy.
In conclusion, I hope this article provided a clear overview of one of the commonly used text generation techniques. In the next installment, we will explore alternative decoding methods.
For those eager to learn more, consider supporting writers on platforms like Medium for the price of a coffee.